









4.7/5 on +200 reviews
Join the 350+ companies and brands that trust us.











4.7/5 on +200 reviews
Join the 350+ companies and brands that trust us.
4.7/5 on +200 reviews
Join the 350+ companies and brands that trust us.
AI-powered customer interaction management solutions
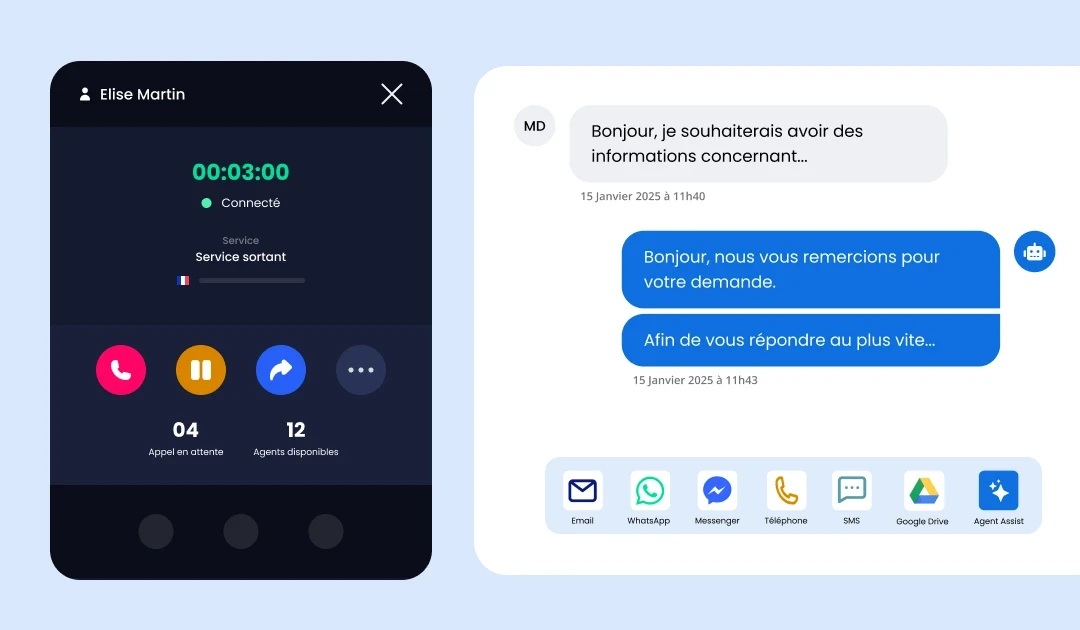

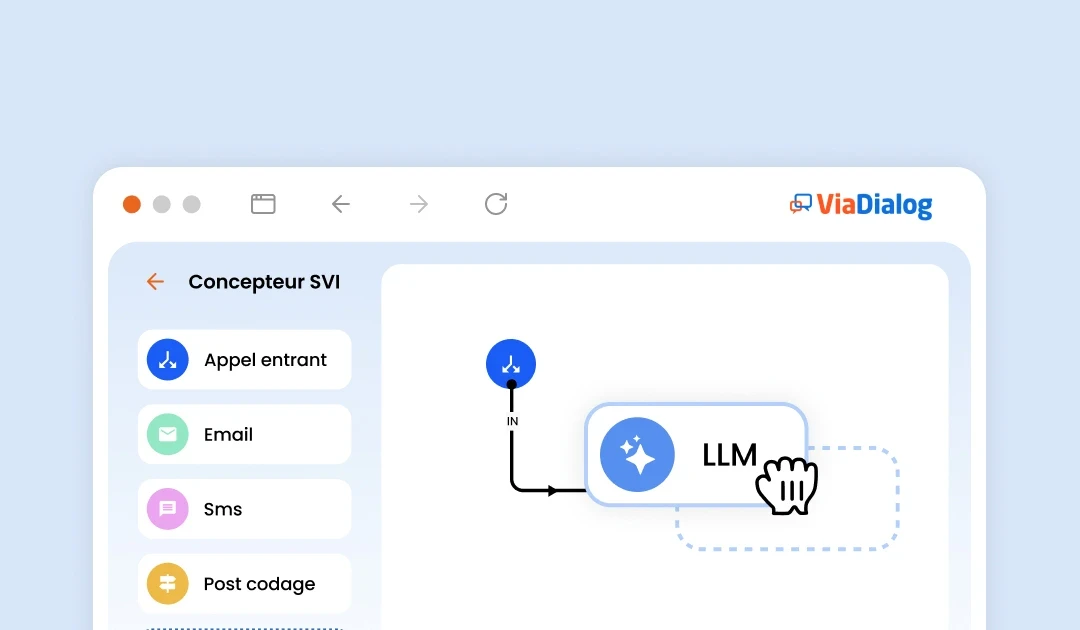
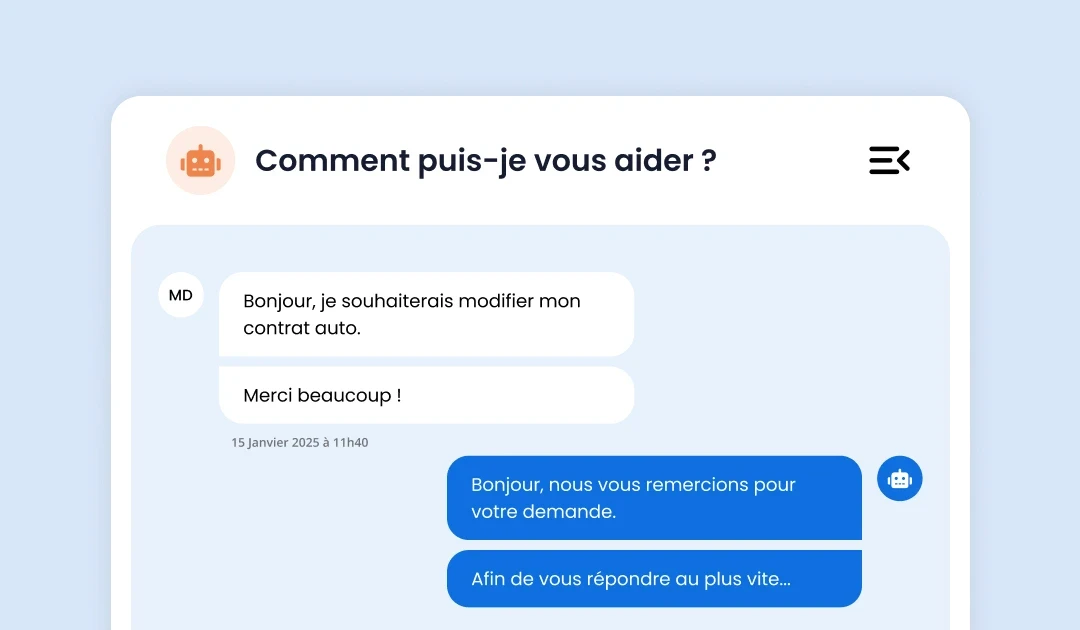



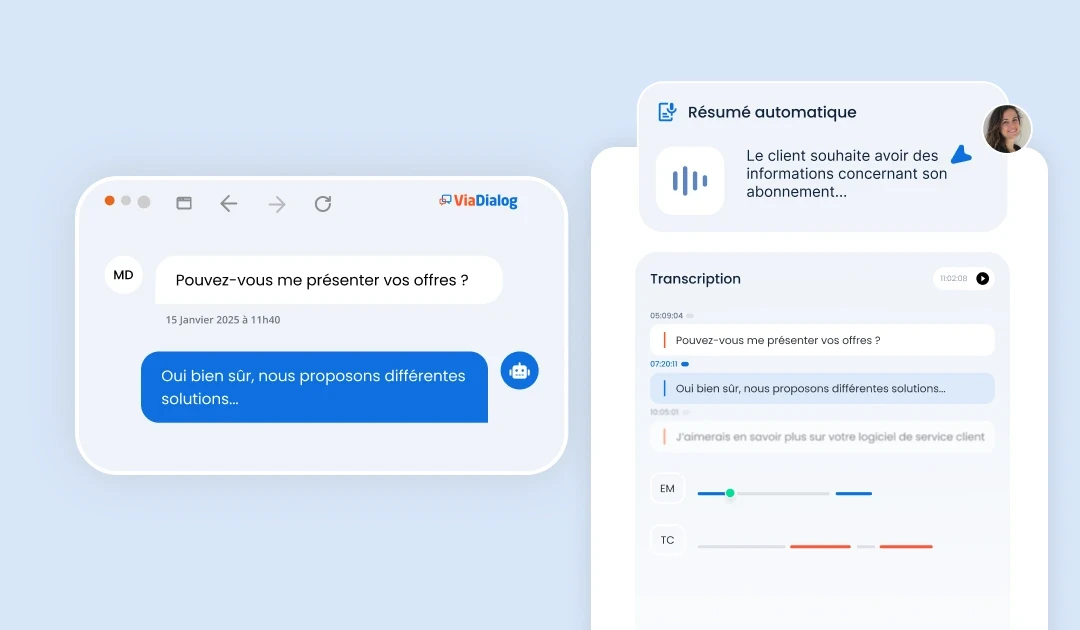





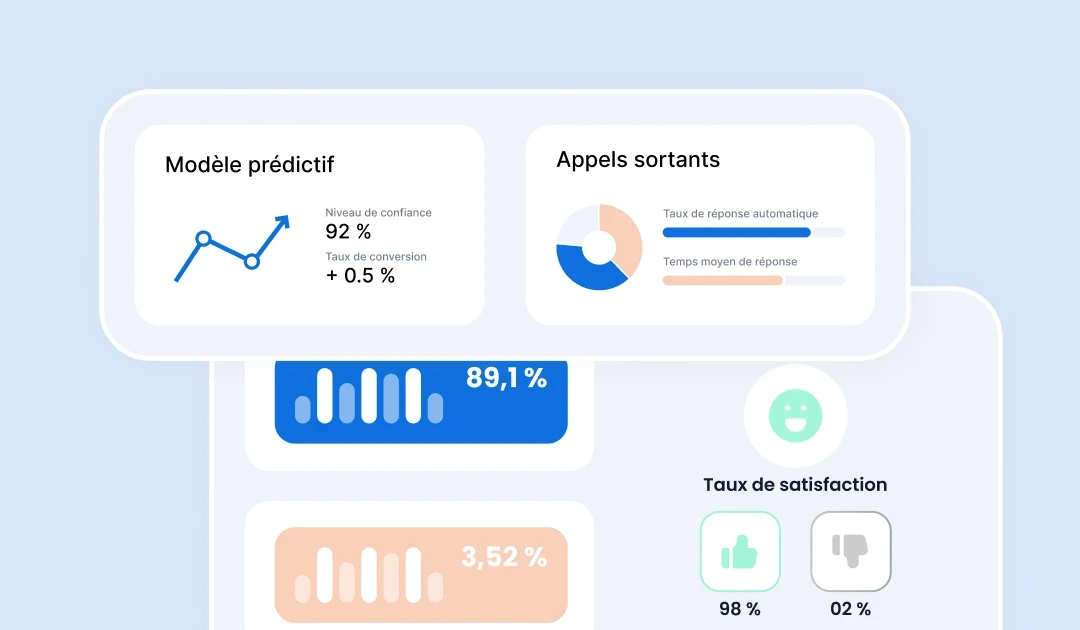



Enhance customer experience and agent performance with complementary AI modules.
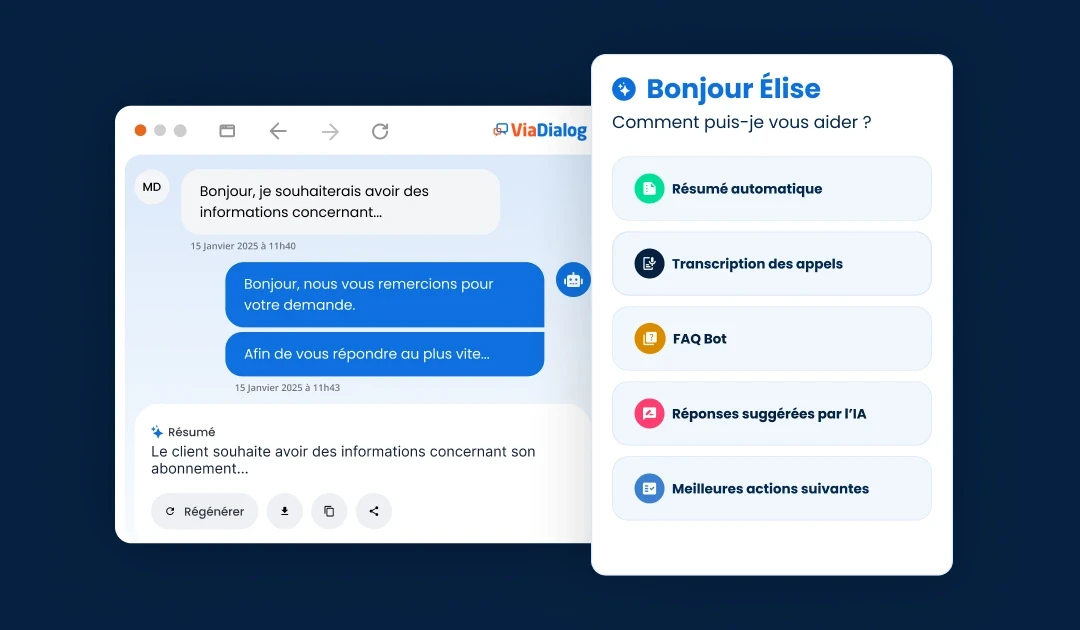
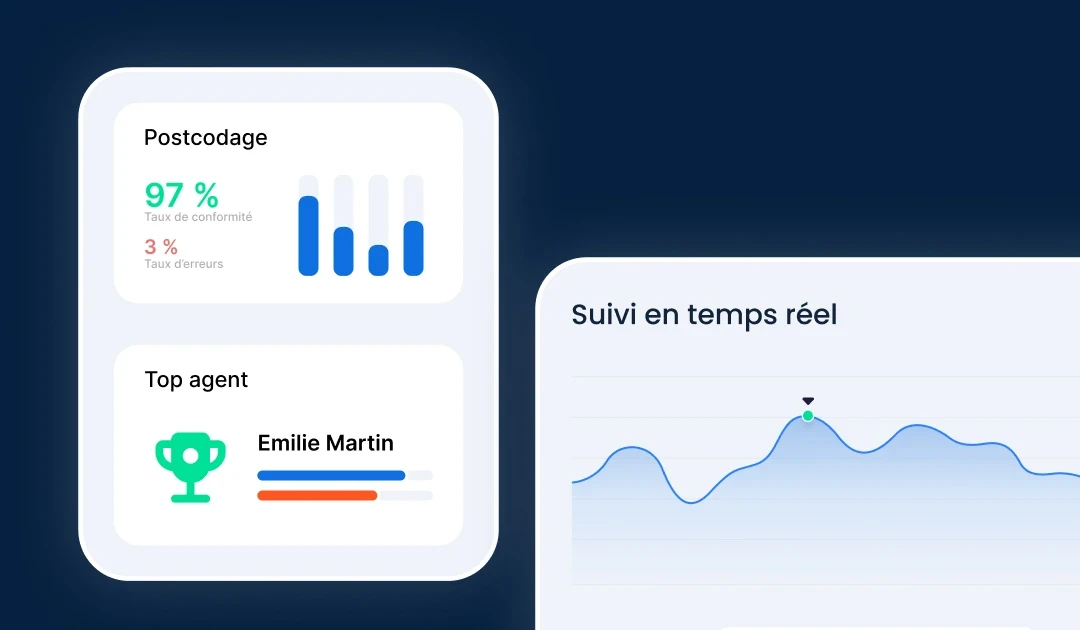
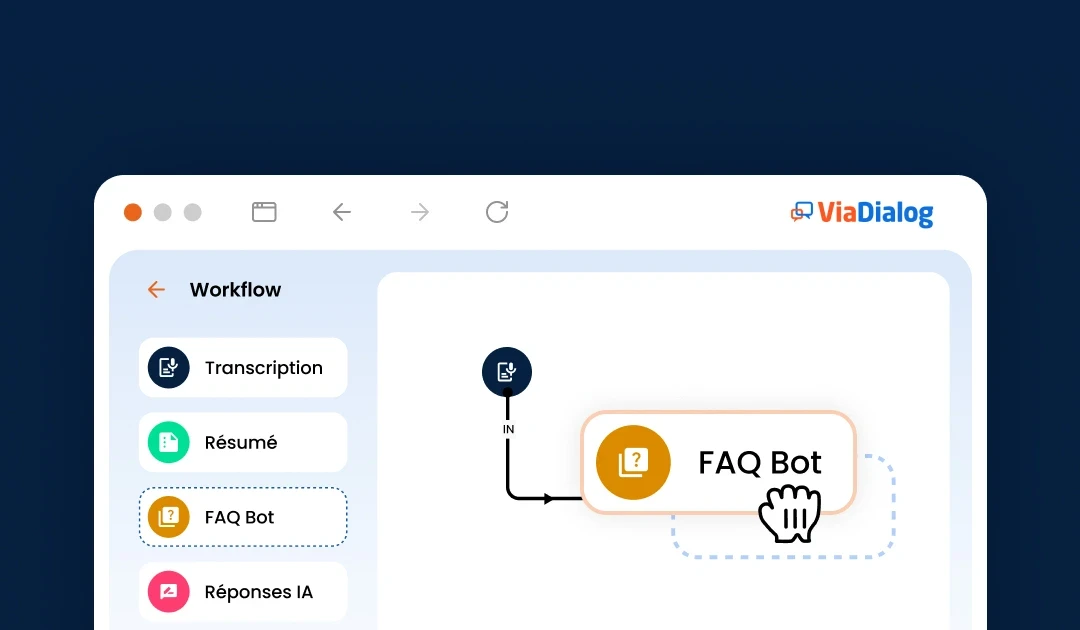
Our advanced AI at the core of the ViaDialog contact center platform
A wide choice of connectors to simplify your data flows
Easily connect to third-party platforms to enhance your customer service software's capabilities.




















Our clients speak about us
IRCEM
Frederic S.

We felt the involvement of the entire team in the success of our project, as it was also ViaDialog's project.
SNCF
Christine D.

We have reduced the number of requests received by our customer support team on Zendesk by 50%.
Asterix Park
David L.

ViaDialog is truly attentive to our needs, all the new features that are implemented on the platforms tomorrow are communicated to the teams, and the supervisors are always supported in maintaining the quality of customer relations.
Sodexo Live
Dominique C.

The solutions offered by ViaDialog are very flexible and intuitive. The product fits our needs perfectly. Moreover, our consultants gain in efficiency and comfort!
Lyon Airport
Florent T.

The ViaSay chatbot reduces the number of support requests handled by agents, allowing for more efficient resource management.
Idea
Jonathan S.

ViaDialog, through the ViaFlow solution, quickly adapted to our requests and our pace throughout the implementation of the tool: from design to production.
Travelski
Aurore Z.

ViaFlow has improved the quality of customer service in two aspects. We have increased the team's performance and productivity, as well as customer satisfaction.
Partélios
Meryam T.

ViaDialog perfectly supported us in a personalized way, from the design of the ViaFlow solution to its implementation.
Elogie Siemp
Mathilde B.

Our agents can now have live data thanks to the dashboard [...]. This allows them to adjust their calls based on the time spent with tenants. If they see that there are many calls, they shorten them.
Connect to Content
Add layers or components to make infinite auto-playing slideshows.
Our clients speak about us
IRCEM
Frederic S.
We felt the involvement of the entire team in the success of our project, as it was also ViaDialog's project.
IRCEM
Frederic S.
We felt the involvement of the entire team in the success of our project, as it was also ViaDialog's project.
SNCF
Christine D.
We have reduced the number of requests received by our customer support team on Zendesk by 50%.
SNCF
Christine D.
We have reduced the number of requests received by our customer support team on Zendesk by 50%.
Asterix Park
David L.
ViaDialog is truly attentive to our needs; all the new features that are implemented on the platforms tomorrow are communicated to the teams, and the supervisors are always supported in maintaining the quality of customer relations.
Asterix Park
David L.
ViaDialog is truly attentive to our needs; all the new features that are implemented on the platforms tomorrow are communicated to the teams, and the supervisors are always supported in maintaining the quality of customer relations.
Sodexo Live
Dominique C.
The solutions offered by ViaDialog are very flexible and intuitive. The product adapts perfectly to our needs. Moreover, our advisors gain in efficiency and comfort! The solution is perfectly suited for remote work, which is becoming the norm.
Sodexo Live
Dominique C.
The solutions offered by ViaDialog are very flexible and intuitive. The product adapts perfectly to our needs. Moreover, our advisors gain in efficiency and comfort! The solution is perfectly suited for remote work, which is becoming the norm.
Lyon Airport
Florent T.
The ViaSay chatbot reduces the number of support requests handled by agents, allowing for more efficient resource management.
Lyon Airport
Florent T.
The ViaSay chatbot reduces the number of support requests handled by agents, allowing for more efficient resource management.
Idea
Jonathan S.
ViaDialog, through the ViaFlow solution, quickly adapted to our requests and pace throughout the implementation of the tool: from design to production.
Idea
Jonathan S.
ViaDialog, through the ViaFlow solution, quickly adapted to our requests and pace throughout the implementation of the tool: from design to production.
Travelski
Aurore Z.
ViaFlow has improved the quality of customer service in two aspects. We have increased the performance and productivity of the team, as well as customer satisfaction.
Travelski
Aurore Z.
ViaFlow has improved the quality of customer service in two aspects. We have increased the performance and productivity of the team, as well as customer satisfaction.
Partélios
Meryam T.
ViaDialog has perfectly accompanied us in a personalized way, from the design of the ViaFlow solution to production.
Partélios
Meryam T.
ViaDialog has perfectly accompanied us in a personalized way, from the design of the ViaFlow solution to production.
Elogie Siemp
Mathilde B.
Our agents can now access real-time data through the dashboard […]. This allows them to adjust their calls based on the time spent with tenants. If they see that there are many calls, they shorten them.
Elogie Siemp
Mathilde B.
Our agents can now access real-time data through the dashboard […]. This allows them to adjust their calls based on the time spent with tenants. If they see that there are many calls, they shorten them.
The proof by numbers
The proof by numbers
From startups to large enterprises, thousands trust ViaDialog.

100%
Hybridization
100%
Hybridization

+50%
Time-saving for agents
+50%
Time-saving for agents

+70%
first contact resolution (FCR)
+70%
first contact resolution (FCR)

Deputy Director of the D2I
François Peyrodie
I particularly appreciate the ergonomics of ViaFlow. The platform is simple, smooth, and intuitive.
Deputy Director of the D2I
François Peyrodie
I particularly appreciate the ergonomics of ViaFlow. The platform is simple, smooth, and intuitive.

÷2
the cost of your customer relationship tools
÷2
the cost of your customer relationship tools
The latest trends in customer relationship
The latest trends in customer relationship
Discover our articles for fresh insights and concrete solutions dedicated to improving customer relations.



Transformez votre relation client avec Viadialog.
70% de résolution au 1er contact
40% de réduction de temps de traitement
+30% de satisfaction client
Conforme RGPD & certifié ISO 22301
Basé en France, opérateur déclaré ARCEP
4.7/5 on +200 reviews




Parlez à un expert ViaDialog.
Obtenez des réponses concrètes pour transformer votre relation client.
🔒 Your data is safe. GDPR compliant, never shared.
Transformez votre relation client avec Viadialog.
70% de résolution au 1er contact
40% de réduction de temps de traitement
+30% de satisfaction client
Conforme RGPD & certifié ISO 22301
Basé en France, opérateur déclaré ARCEP
4.7/5 on +200 reviews
Parlez à un expert ViaDialog.
Obtenez des réponses concrètes pour transformer votre relation client.
🔒 Your data is safe. GDPR compliant, never shared.
Transformez votre relation client avec Viadialog.
70% de résolution au 1er contact
40% de réduction de temps de traitement
+30% de satisfaction client
Conforme RGPD & certifié ISO 22301
Basé en France, opérateur déclaré ARCEP
4.7/5 on +200 reviews
Parlez à un expert ViaDialog.
Obtenez des réponses concrètes pour transformer votre relation client.
🔒 Your data is safe. GDPR compliant, never shared.

