A Gigamodel in a porcelain store… Part II

What changes with Gigamodels?
In each of their fields, Gigamodels establish the new state of the art. Such transitions occur more or less regularly in technology, and actors generally adapt to more efficient new approaches. What makes the transition to Gigamodels potentially different from others?
The race for size
One of the characteristics of Gigamodels is not only that they are large, but that there are increasingly larger ones emerging every year.
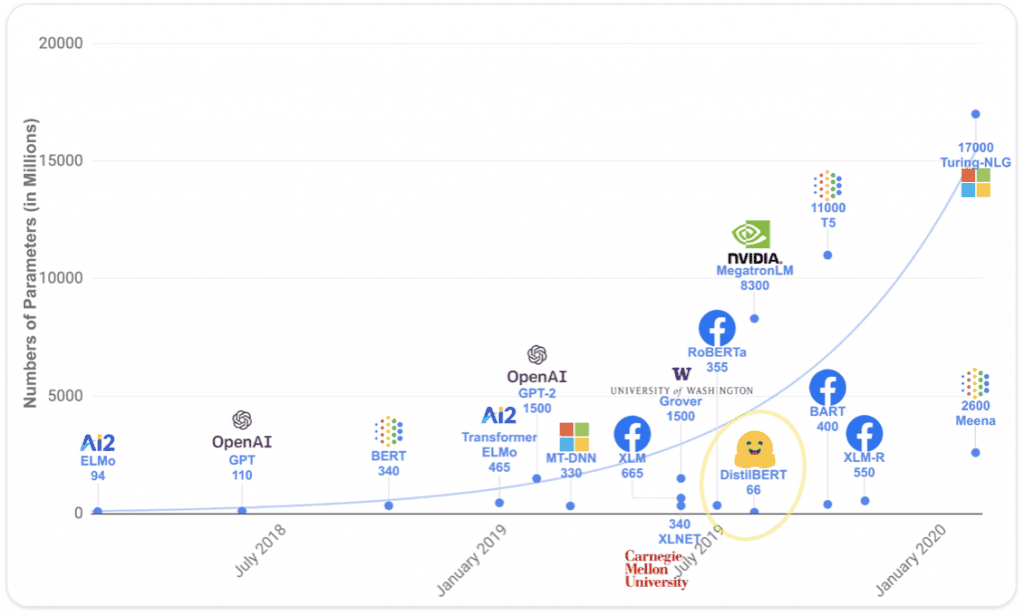
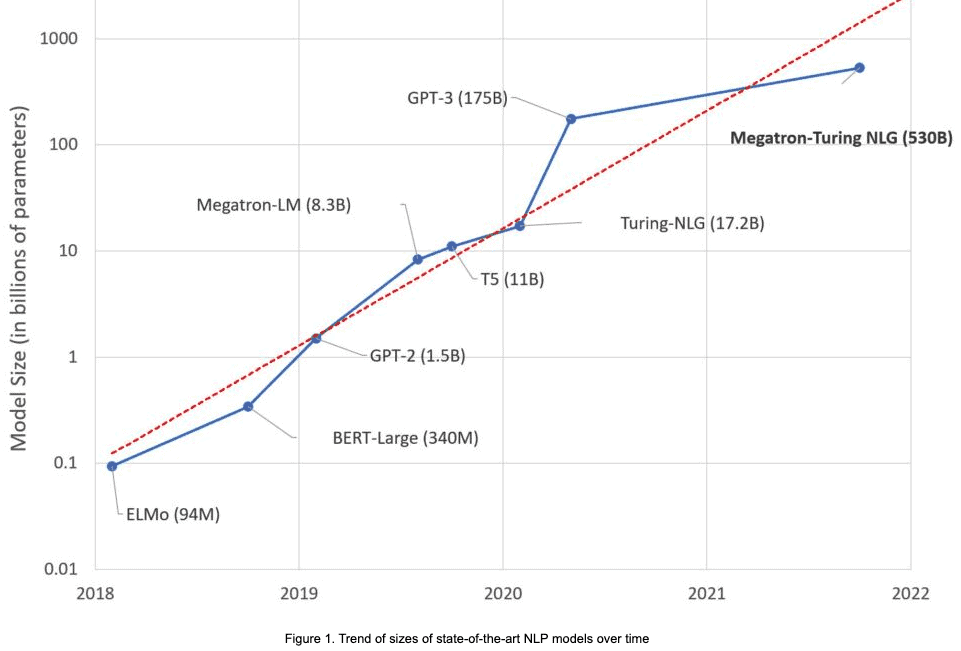
A small handful of actors produce Gigamodels
Regarding learning, the deep learning revolution had already led laboratories and research teams to equip themselves with GPUs (Graphical Processing Units) to launch the learning of the many parameters of deep neural networks. However, learning a Gigamodel requires GPU farm sizes that only a few actors possess globally.
As a result, Gigamodels are almost all produced by a small handful of actors: Google (Elmo, BERT, T5, Lambda, Imagen…), Microsoft+OpenAI (GPT2, GPT3, Dall-E, Whisper..), NVIDIA (Turing NLG, Megatron-Turing NLG with Microsoft, RIVA), Meta — ex-Facebook (XLM, Roberta, wav2vec…)
The emergence of specialized actors
Regarding the use of Gigamodels, whether it be their fine-tuning or their efficient deployment in production, a particular know-how is developing among a few actors, such as HuggingFace, the leading platform for sharing and tooling models, as well as at Microsoft with the ONNX format, or GPU manufacturer NVIDIA, with TensorRT, Triton, NEMO, RIVA…. It is clear that this expertise is key for the business model of these actors, who rely, for one on the revenues from deploying models in their Cloud, for the other on the sale of their GPUs.
The companies producing Gigamodels, such as Google and Microsoft, generally also have a business model involving the sale or rental of processing capacity.
The impact on research and industry
What is the impact of these Gigamodels on research and the industry of cognitive services, language, and speech technologies?
It is probably too early to accurately assess the impact of Gigamodels, but we can already identify the challenges they pose and possible developments.
Research: promise for under-resourced languages; separation of learnings?
Gigamodels carry within them the promise of better responding to applications concerning under-resourced languages or fields, even those with no written record, thanks to pre-trained models complemented with modest-sized supervised corpora, or directly through self-supervised learning. However, experiments still need to be conducted to verify the conditions of effectiveness for these types of approaches.
Another question is whether research will split between a few teams working on the design of the Gigamodels themselves, while the majority of others focus on fine-tuning, producing lighter models, or working with limited data, etc.
Industry: promise of speed; schism around data and Cloud?
For the industry, the promise of Gigamodels is primarily one of reduced entry barriers and decreased needs for supervised learning data.
However, Gigamodels also require specific infrastructures and environments for learning and deployment in production, so we can see two types of users emerging within the industry: those who will rely on specialized actors offering learning and deployment tools in their own cloud, and those who will develop their own capacity in terms of learning and production.
These different types of actors can be represented in the diagram below, taking into account the size of the GPU infrastructures and the size of the data corpora handled.
It appears as a data and infrastructure schism, especially considering the blue blocks. Whether this schism will be confirmed remains to be seen.
The development model of start-ups like HuggingFace seems to bet on this. The actor NVIDIA, which provides both HuggingFace and GAFAM as well as specialized companies and actors, seems ready to support other development models, in case the so-called mole blocks, which regain control over data and infrastructure, become more significant.
In conclusion: reservations, but a course of action
Arriving at the conclusion, it is important to qualify the statement:
First of all, Gigamodels, as promising as they may be, remain a recent phenomenon. They still largely coexist in the industry with hybrid models from the previous generation, learned from already collected and annotated data, which continue to guarantee high performance in their operational domain. The adoption and impact of Gigamodels on the industry are not yet settled and will depend on how agilely industry actors seize them and integrate them into business applications.
Moreover, despite their growing prowess, the limitations of LLMs must be taken into account; increasing the size of the models does not mechanically resolve all complexities of spoken communication, and each model must find its place and operational relevance, which also largely depends on interactions with human users.
Finally, the legal issues surrounding the data feeding these models cannot be overlooked.
All these nuances aside, it is undeniable that Gigamodels are disrupting the state of technology and opening immense and unexplored application possibilities. If European actors do not seize the opportunity and leave it to the large US platforms dominating production and deployment today, they will not have the chance to shape the new ecosystem currently being reconfigured.
The End!






















